


所谓智能音箱,首要条件必然是有一个智能化、自动化的人机交互系统。在上文我们介绍了一个“标准”的智能音箱包含的硬件部分。可以看出,目前的智能音箱本身并不需要多么强悍变态的硬件,普遍只是树莓派的性能水平。目前最畅销的智能音箱是亚马逊Alexa的系列产品,终端销量已经达到千万级别,这也说明了智能音箱产品是一种可以和普通蓝牙音箱一样大规模生产的设备。
但是这些简单的硬件只是驱壳,而基本的操作系统也无外乎Linux和Android等开源操系统基础上进行针对性定制,音箱从听取用户话语到做出相应的语音回复,背后是由一个庞大的云服务体系所处理的千万列工作任务线程中的一支,智能语音涉及的知识库过于庞大,它涵盖了数学[高等数学的函数知识、统计学基础]、声学[声学的基础、理论和测量]、计算机学[数字语音信号处理、编程基础、深度学习]。今天,我们就从软件和后台服务角度,基于目前开放的资料和公开技术平台简单介绍音箱到底是如何听懂人话并说人话的。
自动语音识别[ASR]
语音识别是智能语音交互体系中,系统将人说的话转换成文本文字的过程,和人类交谈类似,智能音箱的“思考”首先是如何将说话理解成对应的文字。现在的智能系统和背后的服务器还无法判断用户的话到底是不是对着音箱说的,因此需智能音箱在待机状态下,麦克风也会保持开机工作,但一般是通过喊特定词语的方式。
从上一篇硬件分析文章中得知,智能音箱首先通过麦克风和ADC模块将声音转化为数字音频信号,但是在数字信号生成时,为了让识别更为快速准确,信号首先会通过硬件或软件DSP等方式进行以下简单处理:
1、声音测向:通过麦克风阵列用于识别语音信息的主要来源方向,便于进一步进行信号增强和降噪等处理;
2、波束形成:在各个方向的麦克风获得的信号经过加权、延时、求和等处理后获得的一个有声场空间指向性的音频信号,用于抑制主声音方向以外其他声音[包括其它方向上其他人同时在说的话];
3、语音增强:通过数字增益等方式提升语音信号的清晰度;
4、降噪:和手机通话类似,将背景的环境噪音以及音箱自身播放的音频内容消除;
5,消除混响和回声:语音信息的声波在室内会由于墙壁等障碍出现多次反射后出现的混响效果,会严重语音识别的精度。
在经历以上几个前期处理步骤后转换成的一个单声道数字音频信号,就是智能音箱接下来将要进行的就是将数字PCM数据转换为文字的工作了。那么此时的语音信号的特性可以参考一下Soomal各类手机的通话测评文章中常见的单声道波形图。

对声音信号的处理是一个非常复杂的分析工作,首先要将音频逐步切分成一个个小段[每段约几十毫秒左右],然后逐段进行分析并通过声学特征提取成一组特征码。对语言学来说,单字或单词的发音由音素构成,各个语言的音素的集合构成了发音的基础,且不同语言之间有所区别[汉语音素集一般为全部声母和韵母,英语的常用标准音素集有39个音素],而音素还能细分成三种状态。
将这组已经转换成特征码的音频数据通过比较音素集和状态集,将帧拼合为状态,再将状态拼合成音素。这个过程内容极其复杂,帧拼合成状态、状态拼合成音素、音素拼合成字词的过程需要用存储了巨大参考数据的“声学模型”和“语言模型”进行概率的计算,而“声学模型”的参数建立需要用大量的语音数据进行训练,还要对付各类地区的口音差异。而语言模型则是通过海量文本的训练得出的统计规律,让转换过程能正确理解特定的语义环境和上下文关联。通过这些步骤,音频信号最终转换成为了文字。由于ASR的详细流程和工作原理过于复杂,这里便不展开叙述。
相应的,如此复杂的语音识别技术需要大量的实验积累,能够自研声学模型、语言模型技术的智能音箱厂商很少,一般会通过开源或购买专业厂商的技术服务,比较知名的有Nuance[苹果Siri、小米等在用]、国内的思必驰等,甚至可以多种识别技术联合共用。语音到文字的识别过程多数情况下可以通过本地运算完成,例如我们常用的各类语音输入法就是典型的语音转文字应用,另一个例子是科大讯飞的语音翻译机晓译,它可以依靠离线的神经网络数据库实现中英日粤多种语言和方言间的相互翻译。

另外,声音特征识别技术除了识别语句外还有其它大量和声频相关的行业应用,并不局限于语音领域,其中一个比较有趣的应用案例就是哼唱曲调识别歌曲,其声学模型主要是来自音乐的旋律特征库,识别成功率率通常也比较高。
自然语言处理和深度学习
自然语言处理的简写为NLP,NLP是一个庞大的系统工程,包含了语音的识别和语音生成的部分。在智能语音交互中,NLP另一个最重要的工作是如何应对前面通过用户语音分析出的文本内容,智能语音的智能家居控制也是目前的一个技术热点,在理解用户的文字含义后又要进行电器的控制。电脑如何识别人类语言的语法、语义、语境,甚至还有在不同的语言见进行翻译,词义的分歧,句法的模糊性和不规范的用语习惯等。如果依靠单个任务程序对逐字反复分析,效率极低,要如何尽快识别文字信息,解决的方法涉及到一个时髦的名词――深度学习。
动物的大脑依靠数量巨大的神经元来接收和传递五官的感知信息,人的大脑内神经元数量就有140亿个,而一个智能手机或智能音箱内的处理器可以运行的线程数量远远达不到这个水准。而深度学习就是一个包含多个隐层的神经网络,用来解决无法用常规的计算机处理难以高效高速解决的问题。这样,一句话、一张图片就可以通过庞大数量的神经元并行计算更快地获得结果。目前深度学习系统多由大型科技企业和大学实验室进行研发,且多数为完全免费开源的项目,已经得到非常广泛的研究和应用。大家较为熟悉的谷歌、微软、Facebook等企业都提供了开源的深度学习系统解决方案,而目前最受欢迎、知名度最高的则是谷歌TensorFlow。
深度学习分为学习和应用两个阶段,以TensorFlow在2017年最经典的应用案例――AlphaGo来看,人工智能理解围棋规则、学习棋谱和如何下棋等和过去的运算方式有了很大变化。尽管AlphaGo本身只是“围棋选手”,但身后的DeepMind和TensorFlow已经可以承担多样化的复杂运算和判断应用。可以说是人工智能、机器学习发展的极大进步,在AlphaGo之后,腾讯等跟进研发的围棋人工智能的棋力也达到了职业选手的水准。

和人的学习一样,机器的深度学习过程需要时间,而单纯依靠CPU的运算并发能力已经不够,因此目前主流的深度学习都支持nVIDIA的GPU通用运算CUDA技术,GPU架构的特殊性可以胜任超大量的并发计算,效率远高于CPU平台。例如,哈尔滨工业大学SCIR实验室的NLP和深度学习的项目,典型的实验设备是以下这样的硬件:
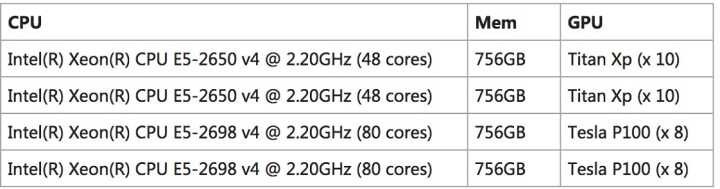
实际上用户量较大的智能音箱的云端服务器也是类似的核心配置,正是由于GPU运算性能在深度学习神经网络大放异彩,也使得NVIDIA的产品重心从桌面PC变成了服务器领域。神经网络和机器学习后所积累的数据可以很好地部分应用于神经网络计算规模相对更小的单机设备[例如AlphaGo2的服务器集群规模就要比1代小很多,但仍然是“集群”]。智能音箱和智能语音的消费类产品还在起步阶段,需要在线的深度运算网络进行分析运算,还无法离线使用。当然,深度学习主要目的是为了正确理解人的语言,具体的应用功能还需要进行拓展,为了方便智能家电厂商和第三方应用开发,许多智能音箱开放了开发接口,更利于增加许多实用性或趣味性更强的小应用。
文本语音转换[TTS]

将文本转换到语音可以说是很常见的功能了,国内互联网起步的早年间就有大量的电子书阅读工具软件。绝大多数音箱不需要通过深度学习网络就能自行将文本转换成语音输出至喇叭。要做到接近人声的流畅自然语序和断字,尤其是文本量巨大多变的人机语音交互中,还是需要一定的技术功力,目前多数智能音箱对于语音输出的品质追求普遍不高,但也在逐步改善之中。例如前段时间央视播出的纪录片《创新中国》中的旁白就采用了人工语音生成,在经过后期处理后已经达到可以接受的水准。另一个正面例子是亚马逊的Alexa,其自动生成的语音水平就非常惊艳和逼真,远超微软和谷歌的产品。
总结和展望
随着深度学习开源项目的逐步普及,其技术也越来越成熟,因此可以看到小米、阿里云等企业也推出了自己的智能音箱产品和标准。虽然各厂家的语音识别和深度学习网络的技术原理大同小异,甚至一个厂商可以为不同的智能语音阵营提供产品[JBL、哈曼等],但作为商业产品,厂商之间的深度学习成果以及神经网络并不是互通共享的,而是处于自立门户和竞争的状态,另外智能家电设备厂商对语音接入的兴趣普遍不高,京东微联的语音功能匮乏就是很好的例子。

在这个人工智能市场热度极高的时期,即使智能音箱并够智能,也已经有了一定的市场影响力,根绝Canalys的统计,2017年全球智能音箱销量突破3000万台,而2018年间则是决定胜负的关键性阶段,市场规模预计在5600万以上,而苹果的智能音箱HomePod也终于在2018年初入场竞争,而比智能音箱硬件本身更重要的是智能语音标准的成败,各品牌也必然在积蓄实力和用户基础,力图让自己掌握在手中的技术成为未来人机语音交互的接口标准。
此帖使用iPhone提交
 京公网安备 11011402011520号
京公网安备 11011402011520号